
PHP Traits: When to Use Them (and Why to Avoid Them)

Traits were introduced to PHP in version 5.4 as a mechanism to share code across classes without inheritance. Years later, PHP 8.x added more capabilities to traits. The question is: did any of that change whether you should use them?
Short answer: no. Here is the full reasoning.
Class Inheritance: The Good, The Bad, The Ugly
Class inheritance is a central concept in object-oriented programming. Some languages like Java limit it to single inheritance; others like C++ allow multiple inheritance. PHP follows the single-inheritance model.
Inheritance can make sense in narrow cases - for example, a hierarchy of UI screen types where a SideBarScreen extends TopNavScreen extends BaseScreen, each adding limited functionality with minimal method overriding.
But it gets messy fast. Subclasses can override methods, members, and constants, making it hard to know what value something actually holds. And once inheritance becomes a key architectural concept rather than a narrow tool, it makes the codebase increasingly hard to follow.
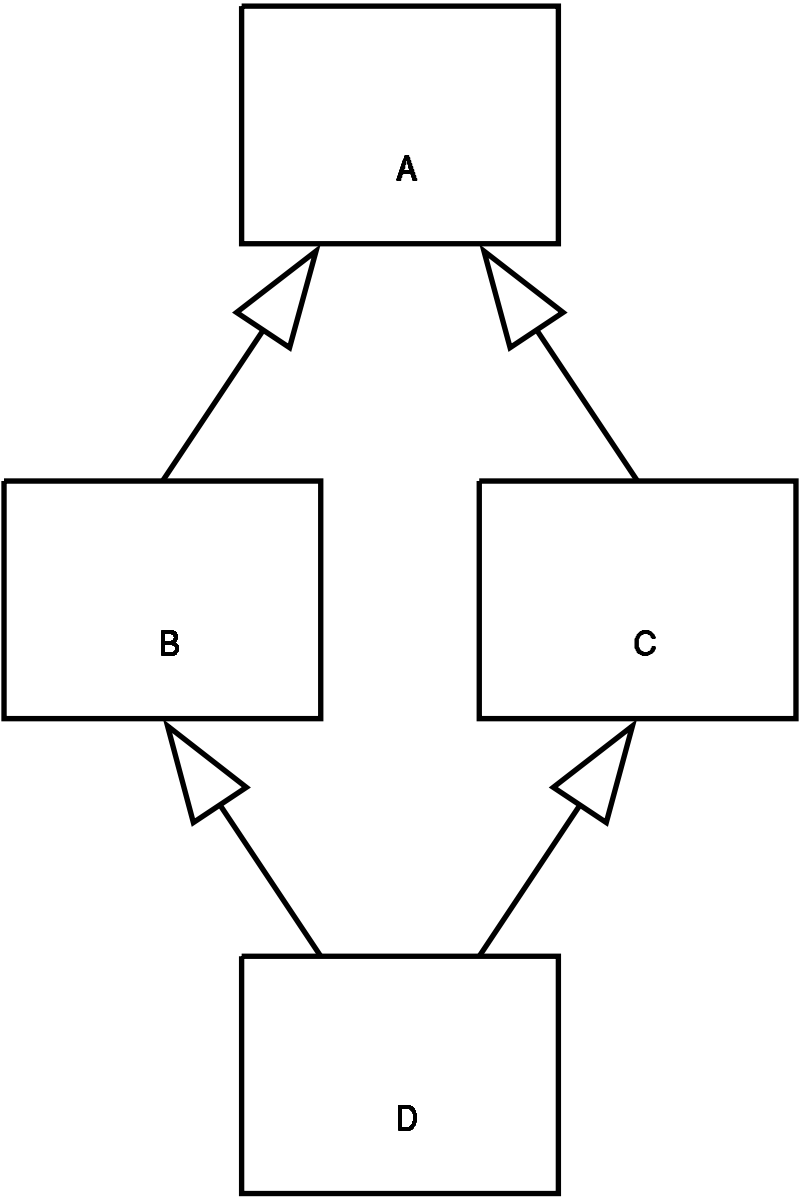
Languages that allow multiple inheritance - C++, for example - demonstrate the diamond problem: if B and C both inherit from A, and D inherits from both B and C, which version of A's method does D get? Traits in PHP introduce the same ambiguity.
What Are Traits?
Traits are a bad compromise to bypass the "limitation" of single inheritance. A class - or even another trait - can use multiple traits, introducing the same diamond problem that multiple inheritance brings. You can even create a loop of traits and it compiles as valid code.
Beyond the diamond problem, traits have other structural weaknesses:
- Traits cannot have private or protected methods/members that are truly private - they assume certain methods/members exist in the consuming class and rely on them implicitly.
- Traits have no "identity" in the type system - you cannot use
instanceofto check for a trait. - Traits cannot be instantiated, so they cannot be unit-tested in isolation.
- Method and constant conflicts between traits require explicit resolution, adding ceremony and hiding intent.
What Changed in PHP 8.x?
The PHP 8 series added capabilities to traits across several versions:
- PHP 8.0 - abstract methods in traits now include signature checking.
- PHP 8.2 - traits can now define constants.
- PHP 8.3 - changed how traits and parent classes handle static properties (migration notes).
These additions made the situation worse, not better. Abstract methods in traits encourage inheritance-based thinking. Constants in traits deepen coupling. Static properties in traits are one of the most reliable ways to make code unpredictable - static state is a well-known source of test isolation failures and hard-to-trace bugs. None of these additions align with SOLID principles.
Interpreting the Impact
Two of the three additions (abstractions and statics) run directly counter to clean architecture. From a SOLID perspective:
- Single Responsibility Principle: a class pulling in several traits quickly accumulates responsibilities from multiple directions, with no clear ownership.
- Hidden dependencies: trait chains obscure what a class actually depends on. Refactoring a trait means hunting down every consumer.
- Testability: traits cannot be instantiated. When a bug lives in a trait, you test it indirectly through every class that uses it, which makes isolation impossible.
- Architecture rot: traits invite "patchwork" design - adding behaviour by stitching in another trait rather than thinking about where responsibility should live.
When Are Traits Acceptable?
There are narrow cases where using a trait is a reasonable trade-off:
- Legacy or enterprise codebases where refactoring to Dependency Injection is not currently worth the cost.
- Utility behaviour that does not influence architecture at all - for example, restricting magic setters:
trait MagicSettersRestrictable {
public function __set(string $name, mixed $value): void {
throw new \Exception("Unsupported magic setters");
}
}Even this is not my preferred approach. Strict typing combined with static analysis tools handles this better without the coupling that traits introduce.
The Alternative: Dependency Injection
I avoid both traits and inheritance in my own architecture. The alternative is Dependency Injection - or as it is sometimes described, composition over inheritance.
With DI, services are registered in a central container, ideally bound against interfaces rather than concrete implementations. Consuming classes only interact with the result of method calls. There is no chaining, no method overriding, no implicit dependency on inherited state. When a concrete implementation needs to change, the consumer does not need to know.
Moving a class file under DI means updating the binding in the container - one place. Moving a trait means updating every use statement across every consumer.
In practice, with Keestash I proved this multiple times through refactorings at scale. The application is layered: the outermost layer handles HTTP requests and receives all dependencies as interfaces. Concrete implementations - database access, email dispatch, object generation - live in layers below. The test suite overrides only a handful of bindings to swap out things like email dispatch, with no trait gymnastics needed.
Conclusion
PHP 8.x did not rehabilitate traits - it added features that deepen the same problems traits have always had. The arguments against them (hidden dependencies, untestability, SRP violations, architecture rot) are unchanged.
If you are currently using traits heavily and considering a refactor, Dependency Injection is the destination. It is more work up front but pays back consistently in testability, predictability, and maintainability.
If you are evaluating traits for a greenfield project: skip them.