Item-Based Collaborative Filtering
Back in 2017, during my Master’s Thesis, I ran this blog in german. Time flies and fast forward to today, I switched to english language very long time ago. For the thesis, I was researching about recommendation systems and Item-Based Collaborative Filtering, among others. My research results were published on this blog, but in German.
This blog post is a re-publish and update of the German version from 2017. Please enjoy reading and get in touch, if you have any questions

For a university project, I’ve been working on recommendation systems, which are typically composed of Collaborative Filtering and Content-Based Recommendation techniques.
In this blog post, I’ll focus on the Collaborative Filtering component, specifically Item-Based Collaborative Filtering. Originally developed by Amazon, Item-Based Collaborative Filtering differs from traditional “User-Based CF.” In User-Based CF, users are represented as n-dimensional item vectors, and their similarity is measured. However, this approach is computationally expensive, with a time complexity of O(MN), where M is the number of users and N is the number of items.
Challenges in User-Based Collaborative Filtering
Amazon’s research on recommendation systems highlights that while most users interact with only a small portion of items, the computational load remains a challenge. Even categorizing users or products only partially alleviates the problem and may lead to less accurate recommendations.
What is Item-Based Collaborative Filtering?
You’ve likely seen Amazon’s “Customers who bought this item also bought” section. This is powered by Item-Based Collaborative Filtering, a scalable algorithm designed to handle large datasets and generate real-time recommendations.
Instead of finding similar users, Item-Based CF identifies products similar to the ones a user has interacted with (purchased, rated, etc.) and combines them into a personalized recommendation list.
The Process
User-Item Matrix
The foundation of this approach is a User-Item Matrix, where each user’s interactions (e.g., purchases or ratings) with items are recorded. Consider the following matrix, where “?” represents a missing rating that needs to be predicted:
| n1 | n2 | n3 | |
| m1 | 0 | 0 | 0 |
| m2 | 1 | 1 | 1 |
| m3 | 1 | 0 | ? |
Here, the goal is to predict the missing value for m3 and n3. This prediction determines whether the item should be recommended.
Measuring Similarity with Cosine Similarity
To predict the missing value, the similarity between items (e.g., n1 and n3) must first be calculated. Cosine Similarity, mentioned by Amazon, is a popular choice for this.
The formula for cosine similarity is:
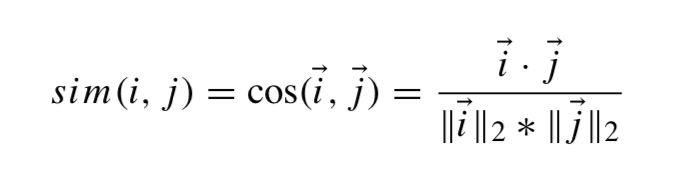
Where i and j are vectors representing two items. The numerator is the dot product, and the denominator is the product of their magnitudes.
For example:
cos(n1,n3) = (0 * 0) + (1 * 1) / sqrt[(0+1)²] * sqrt[(0+1)²] = 0 + 1 / sqrt[1] + sqrt[1] = 1 / 1 = 1
cos(n1,n2) = (0 * 0) + (1 * 1) + (1 * 0) / sqrt[(0+1+1)²] * sqrt[(0+1+0)²] = 1 / 2 = 0,5
cos(n2,n3) = (0 * 0) + (1 * 1) / sqrt[(0+1)²] * sqrt[(0+1)²] = 0 + 1 / sqrt[1] + sqrt[1] = 1 / 1 = 1
This results in the following similarity matrix:
| n1 | n2 | n3 | |
| n1 | 1 | 0,5 | 1 |
| n2 | 0,5 | 1 | 1 |
| n3 | 1 | 1 | 1 |
Predicting Missing Values
To predict m3 ’s rating for n3, we use the weighted sum approach:
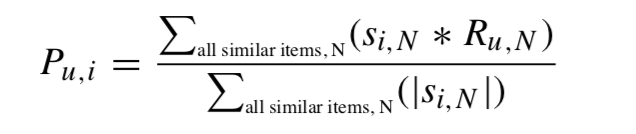
Here, S is the set of similar items. Assuming n1 and n2 are sufficiently similar to n3:
P (u,i) = (1 * 1)+(1 * 0) / 1 + 0 = 1
Conclusion
In this example, user ratings are binary (purchased or not), but the formula can also handle scales, such as 1–5 ratings. Initial tests on paper have yielded promising results, and the complexity is manageable compared to other methods.
Next, I’ll implement this algorithm in code, though it may take some time. Stay tuned for updates!
Further Reading: