Data Transformation with Benthos (now Redpanda Connect)
For a current project, I need to read data from an API, transform and push it to an AWS S3 bucket. Normally I would consider to use a standard programming language for that because there is no “magic” involved. However, one of the requirements is to make data transformation with Benthos, a tool for “Fancy stream processing made operationally mundane”.

Bent-What?
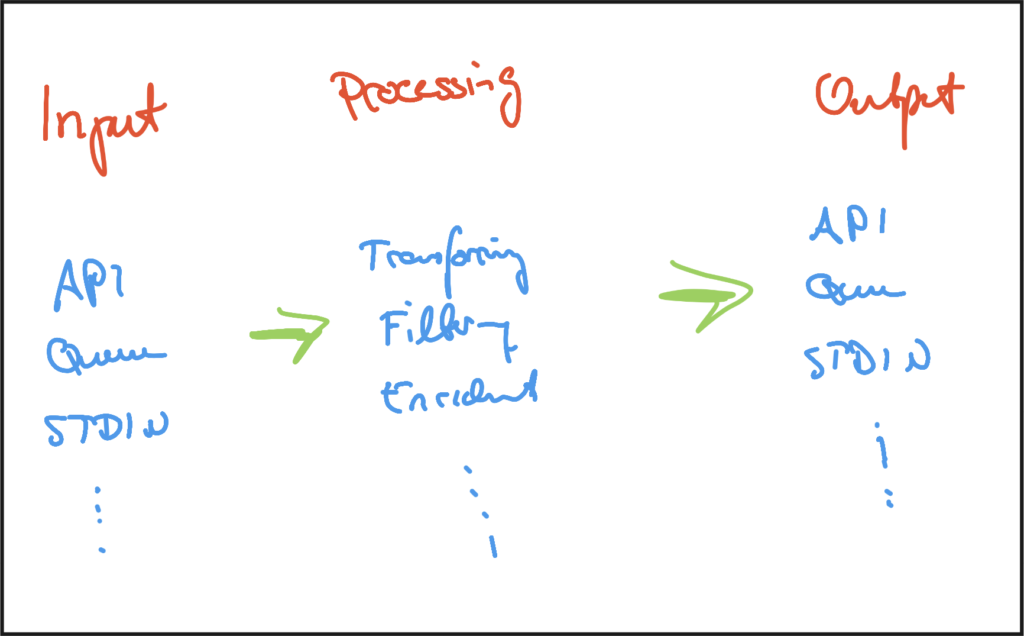
To be honest: I have never heard of Benthos before. The product also describes itself as “boringly easy to use” and thus, there is nothing much about it to say except than: there is an input, one or more processors and an output.
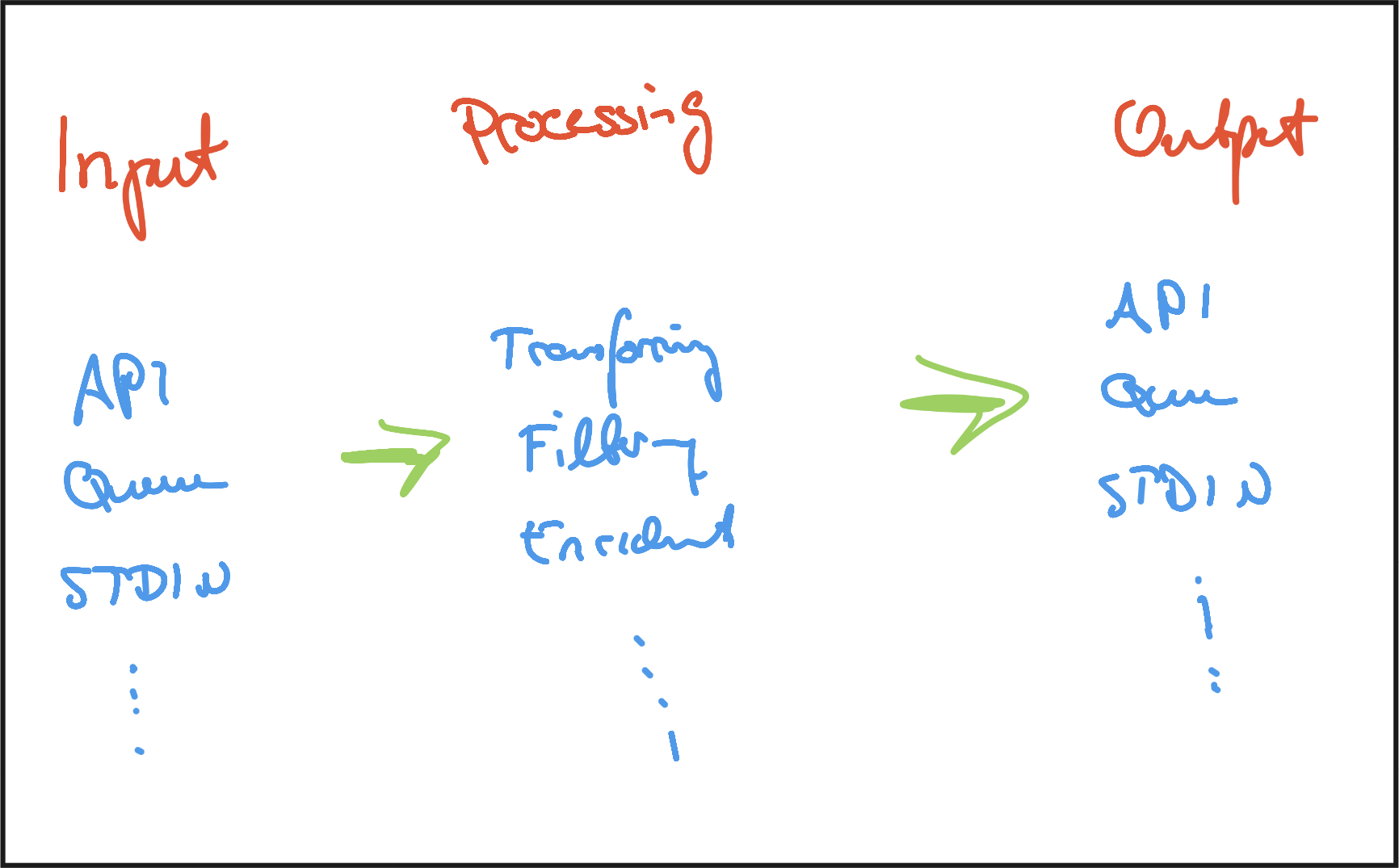
So I started to get an overview over the tool and wanted to get a basic understanding of how it works and what problems it suggests to solve.
The main purpose of Benthos is the transformation of data from an input format to any kind of output format. The input does not necessarily have to be structured (such as JSON or XML), although it makes life easier. The output can be pushed to whatever interface needed and there is built-in support for the majority of services (such as S3, HTTP with Authentication, etc).
Benthos has no dependencies which enables a simple installation on almost every platform and requires a config file “only” to run. The three stages “input”, “processing” and “output” are well structured and easy to understand (thanks to the YAML syntax). Further, there is also exception handling support, such as notifications, dead letter queues, etc. Which really surprised me very positively is the possibility to run unit tests with Benthos.
Bloblang
Bloblang or simply blobl is Benthos’ native mapping language of choice. It promises fast, powerful and safe document mapping and Benthos provides tools for creating extensions to customize it as needed.
Who is Benthos for?
In its self-promotion, Benthos describes itself as a tool for Data Scientists and Data Engineers as there is almost no coding and no (complex) build setups and pipelines needed.
Benthos Example
Playing around with Benthos, I end up with the following:
http:
enabled: true
address: 0.0.0.0:4195
root_path: /
logger:
prefix: benthos
level: INFO
format: json
add_timestamp: true
static_fields:
'@service': benthos
input:
broker:
inputs:
- label: "label_goes_here"
http_server:
path: /
allowed_verbs:
- POST
timeout: 20s
sync_response:
headers:
Content-Type: "application/json"
status: '${! meta("status_code") }'
pipeline:
processors:
- bloblang: |
root.name = "my_first_transformation"
root.occuredAt = this.occuredAt.format_timestamp_unix().format_timestamp_strftime("%Y-%m-%d %H:%M:%S")
- log:
message: '${! content()} meta ${! meta()}'
level: INFO
output:
aws_s3:
bucket: "bucket-address-goes-here"
path: path/goes/here/data.json
tags: {}
content_type: application/json
metadata:
exclude_prefixes: []
region: "region-goes-here"What we are doing here is very simple: Benthos starts a webserver and registers an endpoint (defined under input.broker.inputs.http_server.path) in input. http.root_path defines a general prefix for all incoming requests.
The pipeline section defines the processors. The very simple example above defines only two processors: a bloblang data transformation as well as log for debugging purposes.
The output section writes the data to an S3 bucket.
So, what is Benthos good for?
I would agree with the creators of Benthos that it is boringly easy to use and nothing “special” is going here. I think the real benefit of Benthos is the implementation in Go which makes Benthos fast, reliably and robust. Of course, simple data transformations like above are easy to implement in Python or PHP. But with more complex and thinking in Gigabytes or Terabytes of input/output data, Benthos could be a very good opportunity.
Conclusion
I think Benthos is a niche product and delivers what it promises. However, I think I will have many more touch points with it.
In any case, I also offer my services for Benthos. Please feel free reaching me out if you need Benthos implementation and/or have custom requirements.