Brushing Up My Computer Science Skills: A Deep(er) Dive

This blog post is about Computer Science and my Computer Science Skills and my current skills in it. While I started to work on side projects (such as PHPAlgorithms, Keestash or Unread News), I have neglected my theoretical knowledge (and the practice following the theory).
I want to brush them up a little and utilize this blog post as a summary for my future self and for everyone who is interested in it. If one section becomes to large, I will probably swap it out into an separate blog, let’s see.
My approach is incrementally: First, I set up a plan and denote them as headings here. Then, I will start filling up the chapters. Feel free to reach me out if you think there is something missing or not correct.
Distributed Systems / System Design Related Issues
CAP Theorem: says that a distributed system can only fulfill two of three major components:
- Consistency: whether all nodes in a system are in a consistent state after an (write) operation (data is updated on each node).
- strong consistency: given when a replica (slave) is indistinguishably from the master. The term is widely used and the meaning of “strong” can differ from situation to situation. However, having a strong consistency comes with complexity, low latency and low availability.
- weak/eventually consistency: strong consistency comes with its cost. However, if we are ok with having a small time gap until all replicas get updated (are consistent), weak consistency is a better option.
- more about consistency here.
- (High) Availability: High availability is the ability of a system to operate with a high probability despite the failure of one of its components.
- Partition Tolerance: The system continues to work even though any number of requests are lost or arrive delayed.
Networking
I will first start with the basic structure of the internet in order to have an overview before starting to address other topics. The basic structure depicts the base for almost all activities on a network. From a Computer Science skills point of view, the following points are basics:
Basic Structure
The internet is structured hierarchically. There are three tiers of networks:
- Tier 1 Networks: Are running by big companies (service providers) on multiple backbones that are connecting various regions. Each region has a “Point of Presence” (POP) used by users to access the companies network.
Multiple Tier 1 networks may communicate through “Network Access Points” (NAP) to ensure that computers within a network can communicate with a computer in another vice versa. - Tier 2 Networks: Smaller, usually regional ISP’s that usually provide connections between larger organizations. While communicating with tier 1, tier 2 networks usually does not communicate among each other.
- Tier 3 Networks: Smallest group of ISP’s that provide network connectivity to homes and smaller businesses. They are regional and connect to tier 2 and 1 to provide global internet access.
In reality, the internet is an “interconnected network” of backbones, NAP’s and routesr ensuring that each computer may talk to another one. More information see here.
Transmission Control Protocol (TCP)
TCP is a connection-oriented protocol, which mens, that it establishes and maintains a connection from the client to the server until they finished exchanging messages. Having the following computer science skills makes you a better engineer and deepens the understanding. The following tasks are part of TCP:
- chunks application data into smaller packets
- accepts/puts together packets from the network layer
- manages flow control → coordinates retransmission of malformed packets
- acknowledges all packets that arrive
Packets send over the network may take multiple routes. When arriving on the receiver side, the receiver host sends out an acknowledgement with the information whether the packet arrived properly or needs an retransmission.
TCP together with IP (see below) are the de facto standard for interconnecting networks and computers and make communication happen.
User Datagram Protocol
Because TCP cares about the transmission of packets and retransmit, if necessary, it may cause latency which is in some scenarios a problem (e.g. VoIP).
Therefore, there is another protocol: UDP. UDP does net care about transmission, it just sends out the packets and lets the application layer handle errors. Similar with TCP, understanding UDP is crucial for the set of Computer Science Skills.
Internet Protocol
Every computer in the network has a unique “IP Address”. This address is used to make a communication between computers on a network possible. Knowing IP and IP address handling is also very benefitial from a Computer Science Skills perspective too.
The IP address is structured as a dot separated list of 4 numbers (in decimal format) where each value is within the range 0-255.
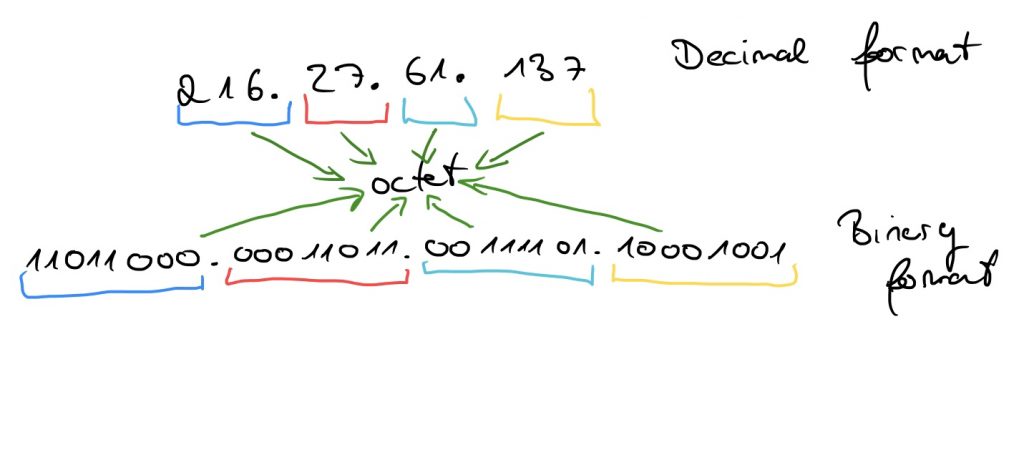
Since we have 4 Octets, we have 4 * 8 = 32 bits, which means, that we have 2^32 = 4.294.967.296 possible IP addresses.
The IP addresses and a couple of other configuration for local devices are usually distributed by a “Dynamic Host Control Protocol” (DHCP) server. This means, that each device in the network gets an IP address which also may change after a certain amount of time (=lease time). When dealing with the lease time, the 50%-rule applies. A device which has an IP address assigned gets also a lease time (usually a couple of days) and asks the DHCP server after 50% of the time for an update. If the server is not available, the client waits another 50% of the remaining time. This process is repeated until the server responds or the lease time is expired. At the end of each lease, the device may get a new IP address or the DHCP server advises it to hold the current one. Web servers, on the other hand, have usually a static IP address attached.
Devices are identified by the DHCP server using the MAC address, which is unique for each computer.
TCP/IP stack
TCP/IP stack represents how data is organised and exchanged over the network using primarly TCP and IP. The stack utilises a series of layers and protocols to transmit data from client to server and vice versa.
TCP/IP is how our internet work and is a set of rules and procedures. TCP/IP and the OSI model are conceptual models for data exchange standards with data being repackaged based on its transport protocols. TCP/IP and OSI differ by the level of specifity:
- OSI is more abstract and not specific to a protocol. It is a framework for general networking systems. OSI has 7 layers.
- TCP/IP is more specific and summarises of a set of protocols. It has 4 layers and is designed after OSI.

- Application Layer: data (HTTP, FTP, POP3, SMTP, SNMP, etc.) is passed to the transport lager.
- Transport Layer: chunks data into TCP segments, adds headers of the choosen protocol (TCP or UDP), ensurs reliability and flow central. TCP knows how to handle with data lost, but does not know the address of the host or the mechanism of getting the packet across.
- Network/Internet Layer: transforms each chunk into an “datagram” (attaching a header that includes the receivers IP address) This layer knows the remote endpoint.
- Physical Layer: transforms packets into bits and bytes and sends over a link (Ethernet, WLAN, etc).
On receiver side, the data goes from down to top.
Domain Names
There is a Top-Level-Doman (TLD), such as .com, .de, .org, etc. Within this TLD every name must be unique (such as “google” in com TLD). Under the name, there is the host (e.g. www). A domain (such as google.com) may contain millions of host, as long as they are unique.
TLD’s are controlled by the “Internet Assigned Numbers Authority” (IANA) in the “Root Zone Database”. There are currently more than 1,000 TLD’s available.
The uniqueness of domain names are guaranteed by registrars, which usually also run their own DNS servers. Each domain registration becomes part of a central domain registration database known as the “whois database”.
DNS Server
Matching domain names to IP addresses by the computer once we want to access an website or write an email is the job of “Domain Name System” (DNS) servers. The lookup action is called as “DNS name resolution”. Again, having the knowledge of DNS is part of basic Computer Science Skills.
There are two major reasons why DNS servers are needed, despite to the fact, that they are not necessary from a technical point of view:
- It is easier to remember a domain name instead of IP addresses (by humans)
- IP addresses may change over time (for both, client and server)
Nowadays, most router contain the (fixed) IP addresses of DNS servers and attach them to the configuration once a device is connected to the router.
DNS service is distributed globally and managed by millions of people. DNS databases gets the most requests in our global network and handles them while also processing data updates.
A device in a network asks a DNS server nearby for the IP address for a given domain name. The DNS server has two options here:
- the IP address is stored in its cache, so it simply returns it
- the DNS server forwards the request to another DNS server and stores the response in its cache (until it expires – TTL).
The second process goes up to the root name servers which are organised hierarchally for wach TLD.
Firewall
A firewall is a barrier to keep away destructive forces away from your network and part of basic Computer Science Skills. It may either be soft- or hardware, but in any case, it filters packets coming through the internet connection. If an incoming packet is flagged as somehow malicious, it is not allowed to pass into your network.
Firewalls implement one or more of the following rules to protect the network (for incoming or outgoing packets):
- Packet Filtering: Packets are analyzed against a set of filters. If passing the filters,
they may reach the network (and the computers in).
Filters may be IP address filtering, which bans/allows certain or a range of IP addresses, domain name filtering
which is the same as IP address filtering but for domain names, protocol filtering, which bans/allows only
a set of protocols (HTTP, SMTP, etc), ports, which are necessary to access some services (80 for HTTP, 21 for FTP, etc) or just specific words or phrases.
- Proxy Service: information is never passed from the internet to the requesting computer,
but to an proxy server, which redirects then to the computer. - Stateful Inspection: Just like packet filtering, but only inspecting certain parts of the
packet.
Some operating systems have built in firewalls as well as some routers which is also considered as
the “hardware firewall”. Because all traffic is routed through the firewall, it is also named as
“gateway”. Modern routers contain all built in firewalls which are customizable/extendable as
described above.
Hypertext Transfer Protocol
HTTP is a stateless protocol, that opens a connection through a socket for each request. For instance, if a HTML page has multiple image tags, the client makes multiple requests to the server: the initial request, which loads the HTML and the following X requests that load the remaining assets (images, JavaScript, etc.).
HTTP Pipelining
HTTP pipeling is a feature of HTTP 1.1 persistent connections. It means that we can send multiple requests on the same socket without waiting to end the response. Due to the fact, that HTTP usually uses TCP/IP at the transport layer and TCP/IP guarantees the order in delivery, HTTP requests may done parallel.
Pipelining was part of the HTTP 1.1 RFC, which includes that servers should support persistent connections. However it is possible that they will not. Servers indicate that they do not support persistent connections when they send a a “connection: close” header. Also, proxies in between my case problems.
HTTP pipeling should only be used for HTTP methods that are “idempotent”. Idempotent requests may apply the same operation many times and it will have the same effect. In general, HTTP GET and HEAD are idempotent.
Pipelining may reduce the TCP/IP packets that are send resulting in faster payloads. Proxy server may also cause problems, for instance when the server supports persistent connections but (one of) the proxy does not.
Cookies
Cookies are very esurial for the web and an acceptable user experience. Technically, they are small pieces of data (text files) that are stored on client side/the browser. The information is sent by the server.
Cookies have a fixed size (4kB) and each domain is allowed to set a certain amount of cookies. Also, the total amount of cookies stored on a browser is limited. If the limit is reached, the browser drops the oldest cookie.
There is no guarantee that a browser will accept or retain cookies for as long as the server requests. The best and only way to make sure that the cookie is set is to refresh the page and check whether the client sends the cookie to the server.
Cookies set by a domain can only read by this domain. There is no way that domain B reads cookies set by domain A (However, there are ways to bypass this limitation).
Cookies are part of the HTTP header and are generally classified in:
- Session Cookies: Are set temporary and deleted when the browser is closed. The server does not set an expiration to the cookie which indicates that the cookie is as a session cookie.
- Persistent Cookies: Persistent cookies are the same as session cookies except that they have an expiration date which indicates how long the cookie should be persisted on the browser.
Third party cookies
While persistent cookies may be used to let a user logged in into an application, they can also used for tracking and advertising. Web applications use several services (e.g. social media like/ share bulbs) and ad banners to make features available on their website. If the user has visited one of theseservices before (e.g. Facebook) and switch over to another website that utilises this service (e.g. a blog), the service can read the cookie it has set despite the fact that it is an other domain. This is generally known as “tracking” or “advertising” cookies, as if males possible to create long term user profiles.
Another Cookies
There are other types of cookies, such as Adobe Flash, Microsoft Silverlight and even Java based cookies. There is also the way of using HTTP headers to track users: etags are used to check the latest version of the page loaded by the client and return a cached version, if the etag header sent by the client is not outdated. Due to their nature, etag headers are unique for a browser (session) and thus, enable tracking easily.
Zombie cookies
Zombie Cookies are cookies that are still available on client side even if the user deletes his browser cache. There are a couple of ways to accomplish this: The web application advises the browser to store the information in all available cookies. If one of the cookies are deleted, the other cookies try to reconstruct it.
Any Bugs or Misstakes? Feel free to get in touch 🙂
Last Update: 20.12.2024 19:22. Change Description: adding CAP Theorem